سلام و وقت بخیر خدمت همراهان وب سایت آموزشی پی وی لرن. با دوره کامل آموزش طراحی کامپایلر در خدمت شما عزیزان خواهیم بود. در این بخش به بررسی تحلیل گر نحوی (Syntax analyser) می پردازیم و مباحثی چون Context-Free Grammar یا گرامر مستقل از متن ، اشتقاق یا Derivation ، چپ ترین اشتقاق (Left-most Derivation) و راست ترین اشتقاق (Left-most Derivation) را بررسی می کنیم. مبحث تحلیل گر نحوی (Syntax analyser) در سه جلسه ارائه خواهد شد.
بررسی تحلیل گر نحوی (Syntax analyser)
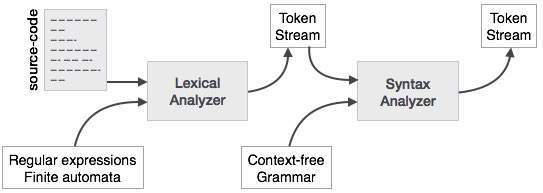
تحلیل گر نحوی یا parsing مرحله دوم کامپایلر است. در این فصل ، ما مفاهیم اساسی را که در ساختار یک parser استفاده می شود ، یاد خواهیم گرفت.
قبلا دیدیم که یک تحلیلگر واژه ای می تواند توکن ها را با کمک عبارات منظم و قوانین الگو مشخص کند. اما یک تحلیلگر واژه ای به دلیل محدودیت عبارات منظم نمی تواند ساختار یک جمله ی مفروض را بررسی کند. عبارات منظم نمی توانند از توکن های متعادل سازی مانند پرانتز را استفاده کنند. بنابراین ، این مرحله از (context-free grammar (CFG-گرامر مستقل از متن استفاده می کند ، که توسط اتوماتای پشته ی یا push-down automata شناخته می شود.
از سوی دیگر ، گرامر مستقل از متن یا CFG یک ابرمجموعه (superset) از دستور زبان منظم است ، همان طور که در زیر نشان داده شده است:

بررسی تحلیل گر نحوی (Syntax analyser)
این بدان معنی می باشد که گرامر منظم (Regular Grammar) نیز بخشی از گرامر مستقل از متن است ، اما برخی از مشکلات نیز وجود دارد ، اما برخی مشکلاتی وجود دارد ، که فراتر از محدوده دستور زبان منظم (Regular Grammar) است. CFG ابزاری مفید در توصیف ساختار زبان های برنامه نویسی است.
در ادامه با مبحث Context-Free Grammar یا گرامر مستقل از متن همراه می شویم.
Context-Free Grammar یا گرامر مستقل از متن
Context-Free Grammar یا گرامر مستقل از متن چیست؟ در ادامه توضیحات بیش تری خواهیم داشت.
در این بخش ، ابتدا تعریف گرامر مستقل از متن یا Context-Free Grammar را خواهیم دید و اصطلاحات به کار رفته در فناوری تجزیه parsing را معرفی خواهیم کرد.
گرامر مستقل از متن یا Context-Free Grammar دارای چهار مؤلفه می باشد :
مجموعه ای از حالات غیر پایانی ها (non-terminals (V. حالات غیر پایانی متغیرهای نحوی هستند که مجموعه ای از رشته ها نشان می دهد. حالت های غیر پایانیا مجموعه ای از رشته ها را تعریف می کنند که به تعریف زبان تولید شده توسط گرامر کمک می کند.
مجموعه ای از توکن ها ، به عنوان نمادهای پایانی (Σ) شناخته می شود. نمادهای پایانی یا Terminalها نمادهای پایه ای هستند که رشته ها بر مبنای آن ها تشکیل می شوند.
مجموعه ای از ترکیب ها (productions (P. ترکیب های یک گرامر روشی است که نمادهای پایانی و غیر پایانی را برای تشکیل رشته ها میتوان ترکیب کرد، مشخص می کند. هر ترکیبی شامل یک نماد غیر پایانی که سمت چپ ترکیب را نامیده می شود ، یک پیکان و یک توالی از توکن ها و / یا نمادهای پایانی است که سمت راست ترکیب می باشد.
یکی از نمادهای غیر پایانی به عنوان نماد آغازین (S) تعیین می شود از جایی که ترکیب شروع می شود.
رشته ها از نماد آغازین با جابجایی مكرر یك غیر پایانی در سمت راست ترکیب مشتق می شوند.
به مثال زیر توجه نمایید.
مثال
مسئله کلمات پالیندوم (palindrome) یعنی کلماتی که از هر دو طرف یکسان خوانده میشوند را در نظر میگیریم (مانند کلمه ی کمک). این واژه ها را به وسیله ی عبارات منظم نمی توان توضیح داد. یعنی {L = { w | w = wR یک زبان منظم نیست. اما می توان آن را به وسیله گرامر مستقل از متن یا CFG توصیف کرد که در ادامه مشخص شده است:
که :
مثال :
| V = { Q, Z, N } Σ = { 0, 1 } P = { Q → Z | Q → N | Q → ℇ | Z → 0Q0 | N → 1Q1 } S = { Q } |
این گرامر ، palindrome را توصیف می کند ، مانند: ۱۰۰۱, ۱۱۱۰۰۱۱۱, ۰۰۱۰۰, ۱۰۱۰۱۰۱, ۱۱۱۱۱ و غیره.
تا این بخش با مبحث Context-Free Grammar یا گرامر مستقل از متن آشنا شدیم.
تحلیل گر نحوی (Syntax analyser)
یک تحلیل گر نحوی (Syntax analyser) یا تجزیه کننده، ورودی را از یک تحلیل گر واژه ای به صورت جریان های توکن می گیرد. تجزیه کننده کد منبع (جریان توکن) را بر اساس قوانین ترکیب برای تشخیص هر گونه خطا در کد آنالیز می کند. خروجی این مرحله یک درخت parse یا درخت تجریه است.
بررسی تحلیل گر نحوی (Syntax analyser) – درخت parse یا درخت تجریه
به این ترتیب ، تجزیه کننده دو کار را انجام می دهد ، یکی تجزیه کد یعنی جستجوی خطاها و دیگری ایجاد یک درخت تجزیه به صورت خروجی فاز.
پیش بینی می شود که تجزیه کننده ها حتی اگر برخی از خطاها در برنامه وجود داشته باشد ، کل کد را تجزیه کنند. تجزیه کننده ها از استراتژی های بازیابی خطا استفاده می کنند ، که در ادامه و در این فصل با آم ها آشنا خواهیم شد.
بررسی اشتقاق یا Derivation
اشتقاق یا Derivation ، اساساً یک توالی از قوانین ترکیب برای دستیابی به رشته ورودی است . در حین تجزیه ، ما برای برخی از شکل های ورودی معتبر دو تصمیم می گیریم:
- تصمیم گیری در مورد نماد غیر پایانی (non-terminal) که باید تعویض شود.
- تصمیم گیری در مورد قوانین ترکیبی که توسط آن نماد غیر پایانی جایگزین خواهد شد.
برای تصمیم گیری این که نماد غیر پایانی با قانون ترکیب جایگزین شود یا نه ، می توانیم دو گزینه داشته باشیم. اشتقاق چپ ترین و اشتقاق راست ترین.
چپ ترین اشتقاق (Left-most Derivation)
اگر صورت جمله یک ورودی اسکن شده و از چپ به راست جایگزین شود ، آن را اشتقاق چپ ترین (Left-most Derivation) می نامند. صورت جمله ای که اشتقاق یافته به روش اشتقاق چپ ترین نیز به نام صورت جمله ای چپ نامیده میشود.
راست ترین اشتقاق (Left-most Derivation)
اگر یک ورودی را از سمت راست به چپ اسکن کنیم و با قوانین ترکیبی و جایگزین نماییم، آن را به عنوان اشتقاق راست ترین (Left-most Derivation) می شناسند. صورت جمله ای اشتقاق یافته از اشتقاق راست ترین ، به نام صورت جمله ای راست نامیده می شود.
در ادامه مثالی را بررسی خواهیم نمود . به مثال توجه نمایید.
قوانین ترکیب:
رشته ی ورودی: id + id * id
اشتقاق چپ ترین (Left-most Derivation) به شکل زیر می باشد:
مثال :
| E → E * E E → E + E * E E → id + E * E E → id + id * E E → id + id * id |
توجه کنید که نماد غیر پایانی سمت چپ ترین non-terminal همیشه در مرحله اول پردازش می شود.
اشتقاق راست ترین (Left-most Derivation) ه شکل زیر می باشد:
مثال :
| E → E + E E → E + E * E E → E + E * id E → E + id * id E → id + id * id |
مبحث بررسی تحلیل گر نحوی (Syntax analyser) را در این بخش به پایان می رسانیم.
کلام پایانی
بررسی تحلیل گر نحوی (Syntax analyser) را در این بخش از آموزش طراحی کامپایلر مورد بحث قرار دادیم. در این راستا مباحثی چون Context-Free Grammar یا گرامر مستقل از متن ، اشتقاق یا Derivation ، چپ ترین اشتقاق (Left-most Derivation) و راست ترین اشتقاق (Left-most Derivation) را بررسی نمودیم. مبحث تحلیل گر نحوی (Syntax analyser) را در جلسه های آینده نیز ادامه خواهیم داد. بنابراین با ادامه ی آموزش ها و وب سایت آموزشی پی وی لرن همراه باشید.
 – طراحی کامپایلر")




