سلام به همه پی وی لرنی های عزیز!
به دوره آموزش دوره آموزش سیستم مدیریت پایگاه داده DBMS خوش آمدید.
Database Management System یا سیستم مدیریت پایگاه داده که به صورت خلاصه به آن DBMS می گویند؛ به فناوری ذخیره و بازیابی اطلاعات کاربران با حداکثر کارآیی در کنار اقدامات امنیتی مناسب اشاره دارد. در این آموزش اصول اولیه سیستم مدیریت پایگاه داده یا DBMS مانند معماری آن، مدل های داده، طرحواره داده ها، استقلال داده ها، مدل E-R، مدل رابطه، طراحی بانک اطلاعاتی رابطه ای، و ذخیره سازی و ساختار پرونده و موارد دیگر را می آموزیم.
در جلسه گذشته به بررسی نقش SQL در سیستم مدیریت پایگاه داده ( DBMS ) پرداختیم. SQL یک زبان برنامه نویسی برای پایگاه داده های Relational است و طراحی شده است که بر روی جبر Relational و حساب tuple Relational کار می کند. SQL به عنوان یک بسته با کلیه توزیع های عمده RDBMS ارائه می شود.
این جلسه را به آشنایی با عادی سازی یا Normalization در سیستم مدیریت پایگاه داده ( DBMS ) اختصاص داده ایم.
عادی سازی یا Normalization در سیستم مدیریت پایگاه داده ( DBMS )
وابستگی عملکردی Functional Dependency
Functional dependency وابستگی عملکردی (FD) مجموعه ای از محدودیت ها بین دو attributes در یک رابطه است. وابستگی عملکردی می گوید اگر دو tuple برای attributes های A1 ، A2 ، … ، An دارای مقادیر یکسان باشند، آن دو tuple باید برای attributes های B1 ، B2 ، … ، Bn نیز مقادیر یکسان داشته باشند.
وابستگی عملکردی با یک علامت فلش (→) یعنی X → Y نشان داده می شود ، که در آن X عملکرد Y را تعیین می کند. attributes های سمت چپ مقادیر attributes های را در سمت راست تعیین می کنند.
اصول آرامسترانگ
اگر F مجموعه ای از وابستگی های عملکردی باشد ، بسته شدن F، با عنوان F + مشخص می شود. اصول آرامسترانگ مجموعه ای از تمام وابستگی های عملکردی است. این اصول مجموعه ای از قوانین است که با استفاده مکرر، بسته شدن وابستگی های عملکردی ایجاد می کند.
- اصل انعکاسی – اگر آلفا مجموعه ای از attributes هاست و بتا is_subset_of alpha است، پس آلفا بتا را نگه می دارد.
- اصل افزایش – اگر a → b نگه داشته شود و y ویژگی را تنظیم کند،ay → by نیز نگه می دارد. این یعنی افزودن صفات در وابستگی ها که وابستگی های اساسی را تغییر نمی دهد.
- اصل انعطاف پذیری – همان قاعده گذرا در جبر است. اگر a → b را نگه داشته و b → c را نگه می دارد؛ آنگاه a → c نگه خواهد داشت. a → b به عنوان تابعی گفته می شود که b را تعیین می کند.
وابستگی عملکردی بدیهی
- Trivial – اگر وابستگی عملکردی (FD) X → Y وجود داشته باشد ، جایی که Y زیرمجموعه X است ، آنگاه FD بدیهی نامیده می شود. FD های بدیهی همیشه نگه داشته می شوند.
- Non-trivial – اگر یک FD X → Y نگه داشته شود، جایی که Y زیرمجموعه X نیست، آنگاه یک FD غیر بدیهی نامیده می شود.
- Completely non-trivial – اگر یک FD X → Y وجود داشته باشد ، جایی که x تقاطع Y = Φ را دارد گفته می شود که یک FD کاملاً غیر بدیهی رخ می دهد.
عادی سازی – Normalization
اگر طراحی پایگاه داده کامل نباشد، ممکن است حاوی ناهنجاری هایی باشد که ممکن است دردسرهای زیادی ایجاد نماید و مدیریت پایگاه داده با وجود این ناهنجاری ها غیر ممکن است.
- بروزرسانی – گاهی موارد داده پراکنده شده و به درستی به یکدیگر پیوند نداشته باشند؛ این موضوع می تواند به موقعیت های عجیبی منجر شود. به عنوان مثال، هنگامی که ما سعی می کنیم یک مورد داده را که نسخه های آن پراکنده شده اند؛ بروزرسانی کنیم، در حالی که تعدادی دیگر با مقادیر قدیمی باقی مانده اند، چند نمونه به درستی به روز می شوند. چنین مواردی پایگاه داده را در حالت متناقض رها می کند.
- ناهنجاری های حذف شده – این حالت موقعی روی می دهد که ما سعی می کنیم یک رکورد را حذف کنیم، اما بخش هایی از آن به دلیل عدم آگاهی حذف نمی شوند و داده ها نیز در جایی دیگر ذخیره می شوند.
- درج ناهنجاری ها – زمانی رخ می دهد که سعی م کنیم داده ها را در یک رکورد وارد کنیم که اصلاً وجود ندارد.
عادی سازی یا Normalization روشی است برای حذف همه این ناهنجاری ها و آوردن پایگاه داده به حالت درست و خوب سابق.
فرم طبیعی اول First Normal Form
فرم طبیعی اول در تعریف روابط (جداول) خود تعریف می شود. این قانون تعریف می کند که همه attributes ها در یک رابطه باید دارای حوزه های اتمی باشند. مقادیر موجود در یک حوزه اتمی واحدهای غیر قابل تفکیک هستند.
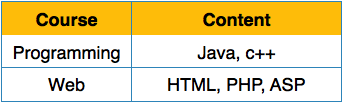
عادی سازی یا Normalization در سیستم مدیریت پایگاه داده ( DBMS )
ما رابطه (جدول) را به شرح زیر مرتب می کنیم تا آن را به فرم طبیعی اول تبدیل کنیم.
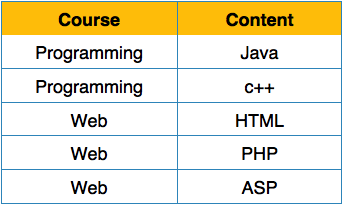
عادی سازی یا Normalization در سیستم مدیریت پایگاه داده ( DBMS )
هر ویژگی باید فقط یک مقدار واحد از دامنه از پیش تعریف شده خود را داشته باشد.
فرم طبیعی دوم Second Normal Form
قبل از آشنایی با در فرم عادی طبیعی دوم ، باید موارد زیر را درک کنیم:
- attribute اصلی – یک attribute، که بخشی از candidate-key است به عنوان یک attribute اصلی شناخته می شود.
- attribute غیر اصلی – به یک attribute، که جزئی از candidate-key نیست گفته می شود که یک attribute غیر اصلی است.
اگر از فرم عادی طبیعی دوم استفاده می کنید؛ باید هر attribute غیر اصلی کاملاً به attribute کلید اصلی وابسته باشد. یعنی اگر X → A نگه داشته شود ، نباید زیر مجموعه مناسبی از X وجود داشته باشد ، که Y → A را نگه به درستی می دارد.
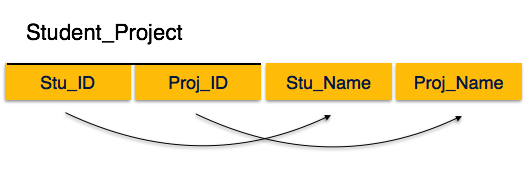
عادی سازی یا Normalization در سیستم مدیریت پایگاه داده ( DBMS )
ما در اینجا در رابطه Student_Project می بینیم که attribute های کلید اصلی Stu_ID و Proj_ID هستند. طبق این قانون ، attribute های غیر کلیدی، یعنی Stu_Name و Proj_Name باید به هر دو وابسته باشند و به هر یک از attribute های اصلی به طور جداگانه وابسته نباشند. اما می دانیم که Stu_Name توسط Stu_ID قابل شناسایی است و Proj_Name را می توان توسط Proj_ID بطور مستقل شناسایی کرد. به این وابستگی جزئی گفته می شود که در فرم طبیعی دوم مجاز نیست.
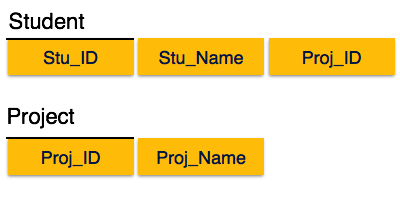
عادی سازی یا Normalization در سیستم مدیریت پایگاه داده ( DBMS )
ما رابطه را به دو صورت شکسته ایم – همانطور که در تصویر بالا نشان داده شده است – بنابراین هیچ وابستگی جزئی وجود ندارد.
فرم طبیعی سوم Third Normal Form
برای اینکه رابطه در فرم طبیعی سوم باشد، باید به شکل طبیعی دوم باشد و موارد زیر را فراهم نماید:
- هیچ صفت غیر اصلی به طور انتقالی وابسته به attribute کلید اصلی نباشد.
- برای هرگونه وابستگی عملکردی غیر بدیهی ، X → A، آنگاه :
– X یک superkey است یا
– A یک attribute اصلی است.

عادی سازی یا Normalization در سیستم مدیریت پایگاه داده ( DBMS )
درمی یابیم که در رابطه Student_detail فوق، Stu_ID می تواند attribute اصلی و کلیدی اصلی باشد. ما می دانیم که City می تواند توسط Stu_ID و همچنین Zip شناسایی شود. نه Zip ما superkey و نه City ما attribute است. علاوه بر این، Stu_ID ip Zip → City، بنابراین وابستگی انتقالی وجود دارد.
برای برقراری این رابطه به شکل طبیعی سوم، ما رابطه را به دو رابطه زیر تقسیم می کنیم:
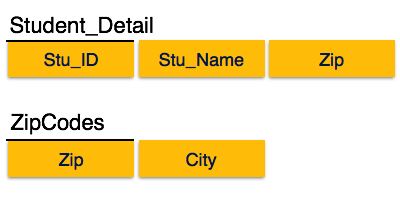
عادی سازی یا Normalization در سیستم مدیریت پایگاه داده ( DBMS )
فرم عادی Boyce-Codd
فرم طبیعی (Boyce-Codd (BCNF فرمت سوم نرمال با شرایط سخت است. BCNF عنوان می کند که:
- برای هرگونه وابستگی عملکردی غیر وابسته، X → A ،X باید یک super-key باشد.
در تصویر بالا ، Stu_ID می تواند super-key ما در رابطه Student_Detail باشد و Zip نیز super-key رابطه ZipCodes است.
و
که تأیید می کند که هر دو روابط در BCNF هستند.
سخن پایانی
در این جلسه عادی سازی Normalization در سیستم مدیریت پایگاه داده را بررسی کردیم؛ اگر طراحی پایگاه داده کامل نباشد، ممکن است حاوی ناهنجاری هایی باشد که ممکن است دردسرهای زیادی ایجاد نماید و مدیریت پایگاه داده با وجود این ناهنجاری ها غیر ممکن است.
در جلسه بعد می خواهیم شما را با Joins در سیستم مدیریت پایگاه داده آشنا نماییم.
با پی وی لرن همراه باشید.
")




