سلام به همه پی وی لرنی های عزیز!
به دوره آموزش دوره آموزش سیستم مدیریت پایگاه داده DBMS خوش آمدید.
Database Management System یا سیستم مدیریت پایگاه داده که به صورت خلاصه به آن DBMS می گویند؛ به فناوری ذخیره و بازیابی اطلاعات کاربران با حداکثر کارآیی در کنار اقدامات امنیتی مناسب اشاره دارد. در این آموزش اصول اولیه سیستم مدیریت پایگاه داده یا DBMS مانند معماری آن، مدل های داده، طرحواره داده ها، استقلال داده ها، مدل E-R، مدل رابطه، طراحی بانک اطلاعاتی رابطه ای، و ذخیره سازی و ساختار پرونده و موارد دیگر را می آموزیم.
در جلسه گذشته به آشنایی با ساختار فایل در سیستم مدیریت پایگاه داده ( DBMS ) پرداختیم؛ داده ها و اطلاعات نسبی به صورت دسته جمعی در قالب فایل ذخیره می شوند. فایل دنباله ای از رکورد های ذخیره شده در قالب باینری است. یک درایو دیسک به چندین بلوک تبدیل می شود که می تواند رکوردها را ذخیره کند. فایل های رکورد بر روی آن بلوک های دیسک نقشه برداری می شوند.
در این جلسه به آشنایی با Indexing در سیستم مدیریت پایگاه داده ( DBMS ) می پردازیم.
آشنایی با Indexing در سیستم مدیریت پایگاه داده ( DBMS )
همان طور که می دانید داده ها به صورت رکورد ذخیره می شوند. هر رکورد دارای یک فیلد کلیدی است که به تشخیص منحصر به فرد آن کمک می کند.
Indexing یک تکنیک ساختار داده برای بازیابی کارآمد فایل ها از فایل های پایگاه داده بر اساس برخی از ویژگی هایی است که Indexing در آنها انجام شده است. Indexing در سیستم های پایگاه داده مشابه آنچه در کتاب ها می بینیم است.
Indexing بر بر اساس indexing attributes تعریف می شود. Indexing می تواند از انواع زیر باشد:
- Primary Index – Primary Index در thdg داده مرتب شده تعریف می شود. فایل داده در یک فیلد کلیدی سفارش داده می شود. قسمت اصلی به طور کلی کلید اصلی رابطه است.
- Secondary Index – Secondary Index ممکن است از فیلدی تولید شود که یک candidate key است و در هر رکورد دارای ارزش منحصر به فرد است، یا غیر کلیدی با مقادیر تکراری.
- Clustering Index – Clustering Index بر روی فایل داده سفارش داده شده تعریف می شود. فایل داده بر اساس یک فیلد غیر کلیدی مرتب می شود.
مرتب سازی Indexing به دو صورت شکل می گیرد:
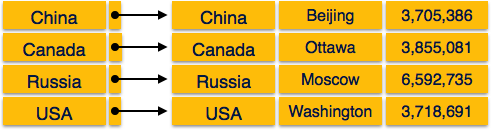
Dense Index
در Dense Index برای هر مقدار کلید جستجو در پایگاه داده یک رکورد Index وجود دارد که باعث می شود جستجو سریعتر شود اما به فضای بیشتری نیاز دارد تا بتواند رکوردهای Index خود را ذخیره کند. سوابق Index حاوی مقدار کلید جستجو و یک اشاره گر به رکورد واقعی روی دیسک هستند.
آشنایی با Indexing در سیستم مدیریت پایگاه داده ( DBMS )
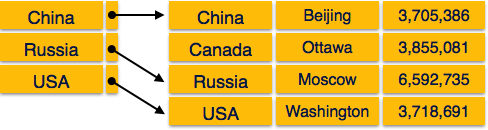
Sparse Index
در Sparse Index، رکوردهای Index برای هر کلید جستجو ایجاد نمی شود. یک رکورد Index در اینجا شامل یک کلید جستجو و یک اشاره گر واقعی به داده های موجود در دیسک است. برای جستجوی یک رکورد ، ابتدا با استفاده از رکورد Index اقدام می کنیم و به مکان واقعی داده ها می رسیم. اگر داده های مورد نظر ما جایی نباشد که مستقیماً با دنبال کردن این Index به آنها برسیم، سیستم تا زمانی که داده های مورد نظر پیدا نشود، جستجوی متوالی را آغاز می کند.
آشنایی با Indexing در سیستم مدیریت پایگاه داده ( DBMS )
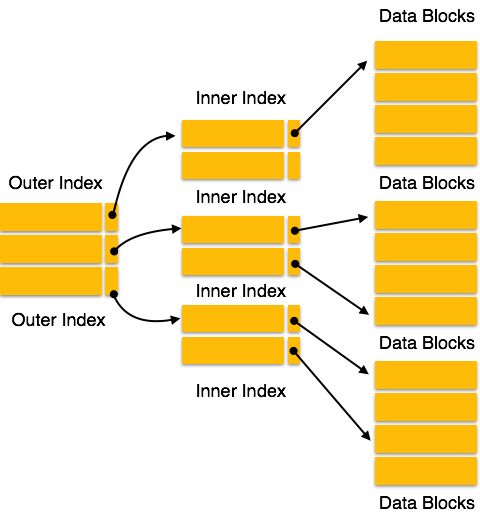
Index چند سطحی
Index چند سطحی شامل مقادیر کلید جستجو و نشانگرهای داده است. Index چند سطحی به همراه فایل های پایگاه داده واقعی روی دیسک ذخیره می شود. با افزایش اندازه پایگاه داده، اندازه Index ها نیز افزایش می یابد آن گاه نیاز به نگه داشتن رکوردهای Index در حافظه اصلی برای سرعت بخشیدن به عملیات جستجو وجود دارد. اگر از Index سطح یک استفاده شود ، نمی توان Index بزرگی را در حافظه نگه داشت که به چندین دیسک دسترسی پیدا کند.
آشنایی با Indexing در سیستم مدیریت پایگاه داده ( DBMS )
ایندکس چند سطحی در تجزیه Index به چندین Index کوچکتر کمک می کند تا دورترین سطح آنقدر کوچک باشد که بتوان آن را در یک بلوک دیسک ذخیره کرد که به راحتی در هر مکانی در حافظه اصلی جای می گیرد.
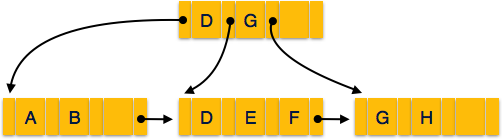
B+ Tree
B+ Tree یک درخت جستجوی باینری متعادل است که از یک قالب Index چند سطحی پیروی می کند. leaf node های B+ Tree نشانگرهای داده واقعی را نشان می دهد. B+ Tree تضمین می کند که تمام leaf node در همان ارتفاع باقی بمانند، بنابراین متعادل می شوند. leaf node ها با استفاده از لیستی از لینک ها مرتبط می شوند. بنابراین ، یک B+ Tree می تواند از دسترسی تصادفی و همچنین دسترسی متوالی پشتیبانی کند.
ساختار B+ Tree
هر leaf node در فاصله مساوی از root node قرار دارد. B+ Tree از ترتیب n است که در آن n برای هر B+ Tree ثابت است.
آشنایی با Indexing در سیستم مدیریت پایگاه داده ( DBMS )
nodes های داخلی
- nodes های داخلی (non-leaf) حداقل نشانگرهای ⌈n / 2⌉ به جز root node دارند.
- حداکثر، یک node داخلی می تواند حاوی نشانگرهای n باشد.
Leaf nodes ها یا node های برگ
- Leaf nodes حاوی حداقل نشانگرهای رکوردهای ⌈n/2⌉ و مقادیر کلیدی ⌈n / 2⌉ هستند.
- حداکثر ، یک Leaf node می تواند حاوی نشانگرهای رکورد و مقادیر کلیدی n باشد.
- هر Leaf node حاوی یک نشانگر بلوک P برای اشاره به Leaf node بعدی است و یک لیست از لینک ها را تشکیل می دهد.
B+ Tree Insertion
- B+ tree ها از پایین پر می شوند و هر ورودی در Leaf node انجام می شود.
- اگر leaf node سرریز شود:
– node را به دو قسمت تقسیم کنید.
– تقسیم بندی در ⌊i = ⌊(m+1)/2
– i های ورودی اولیه در یک node ذخیره می شوند.
– بقیه ورودی ها (i+1 onwards) به یک node جدید منتقل می شوند.
– کلید ith در parent یا والد leaf تکثیر می شوند. - اگر یک non-lea سرریز شود:
– node را به دو بخش تقسیم کند.
– تقسیم بندی node در ⌈i = ⌈(m+1)/2
– وارد کردن i هایی که در یک node نگهداری می شوند.
– انتقال بقیه ورودی ها به node جدید.
B+ Tree Deletion
- ورودی های B+ Tree در leaf nodes ها حذف می شوند.
- ورودی هدف جستجو شده و حذف می شود.
– اگر این یک گره داخلی (internal node) است ، ورودی را از موقعیت سمت چپ حذف کرده و جایگزین کنید. - پس از حذف، underflow مورد آزمایش قرار می گیرد:
– اگر underflow رخ داد، ورودی ها را از node های سمت چپ به آن توزیع کنید. - اگر توزیع از چپ امکان پذیر نیست، پس از آن:
– از node های سمت راست آن توزیع کنید. - اگر توزیع از چپ یا راست امکان پذیر نیست، پس از آن:
– node را با چپ و راست در آن ادغام کنید.
سخن پایانی
در این جلسه به آشنایی با Indexing در سیستم مدیریت پایگاه داده ( DBMS ) پرداختیم؛ داده ها به صورت رکورد ذخیره می شوند. هر رکورد دارای یک فیلد کلیدی است که به تشخیص منحصر به فرد آن کمک می کند.
Indexing یک تکنیک ساختار داده برای بازیابی کارآمد فایل ها از فایل های پایگاه داده بر اساس برخی از ویژگی هایی است که Indexing در آنها انجام شده است. Indexing در سیستم های پایگاه داده مشابه آنچه در کتاب ها می بینیم است.
در جلسه آینده قرار است به سراغ آشنایی با مفهوم Hashing در سیستم مدیریت پایگاه داده برویم.
با پی وی لرن همراه باشید.
")




