سلام به همه پی وی لرنی های عزیز!
به دوره آموزش دوره آموزش سیستم مدیریت پایگاه داده DBMS خوش آمدید.
Database Management System یا سیستم مدیریت پایگاه داده که به صورت خلاصه به آن DBMS می گویند؛ به فناوری ذخیره و بازیابی اطلاعات کاربران با حداکثر کارآیی در کنار اقدامات امنیتی مناسب اشاره دارد. در این آموزش اصول اولیه سیستم مدیریت پایگاه داده یا DBMS مانند معماری آن، مدل های داده، طرحواره داده ها، استقلال داده ها، مدل E-R، مدل رابطه، طراحی بانک اطلاعاتی رابطه ای، و ذخیره سازی و ساختار پرونده و موارد دیگر را می آموزیم.
در جلسه گذشته به آشنایی با Indexing در سیستم مدیریت پایگاه داده ( DBMS ) پرداختیم؛ داده ها به صورت رکورد ذخیره می شوند. هر رکورد دارای یک فیلد کلیدی است که به تشخیص منحصر به فرد آن کمک می کند.
Indexing یک تکنیک ساختار داده برای بازیابی کارآمد فایل ها از فایل های پایگاه داده بر اساس برخی از ویژگی هایی است که Indexing در آنها انجام شده است. Indexing در سیستم های پایگاه داده مشابه آنچه در کتاب ها می بینیم است.
در این جلسه قرار است به سراغ آشنایی با Hashing در سیستم مدیریت پایگاه داده ( DBMS ) برویم.
آشنایی با Hashing در سیستم مدیریت پایگاه داده ( DBMS )
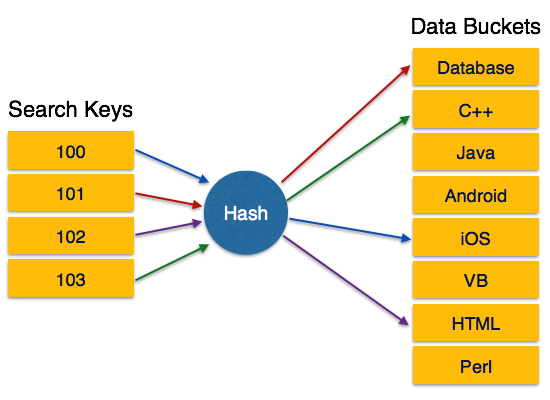
برای یک ساختار بزرگ پایگاه داده؛ جستجو برای یافتن تمام مقادیر index از طریق تمام سطح آن و سپس رسیدن به بلوک داده مقصد برای بازیابی اطلاعات مورد نظر؛ تقریباً کار خیلی خیلی سختی است. اما دست ما آنچنان هم خالی نیست! Hashing یک تکنیک مؤثر برای محاسبه محل مستقیم رکورد داده بر روی دیسک بدون استفاده از ساختار index است.
Hashing از توابع Hash با کلیدهای جستجو به عنوان پارامترها برای تولید آدرس رکورد داده استفاده می کند.
سازماندهی Hash
- Bucket – یک Hash داده ها را در قالب Bucket ذخیره می کند. Bucket یک واحد ذخیره سازی محسوب می شود. یک Bucket به طور معمول یک بلوک کامل دیسک را ذخیره می کند، که به نوبه خود می تواند یک یا چند رکورد را ذخیره کند.
- Hash Function – یک تابع Hash یا Hash Function یک تابع mapping است که تمام مجموعه کلیدهای جستجو K را به آدرسی که رکورد واقعی در آن قرار دارد، نگاشت می کند. این تابع از کلیدهای جستجو تا آدرس Bucket را شامل می شود.
Static Hashing – هشینگ استاتیک
در Static Hashing یا هش استاتیک وقتی یک مقدار کلید جستجو ارائه می شود، تابع Hash همیشه همان آدرس را محاسبه می کند. به عنوان مثال ، اگر از تابع hash mod-4 استفاده شود ، فقط ۵ مقدار تولید می شود. آدرس خروجی همیشه باید برای آن عملکرد یکسان باشد. تعداد Bucket های ارائه شده در همه زمان ها بدون تغییر باقی می ماند.
آشنایی با Hashing در سیستم مدیریت پایگاه داده ( DBMS )
Operation
- Insertion – هنگامی که یک رکورد باید برای استفاده از Static Hashing وارد شود ، تابع هش h آدرس Bucket را برای کلید جستجو K محاسبه می کند، جایی که رکورد در آن ذخیره می شود.
آدرس Bucket برابر است با = (h(K - Search – هنگامی که یک رکورد نیاز به بازیابی دارد، می توان از همان تابع هش برای بازیابی آدرس Bucket محل ذخیره داده ها استفاده کرد.
- Delete – این سؤال ساده ای است که به دنبال یک عمل حذف (deletion operation) همراه است.
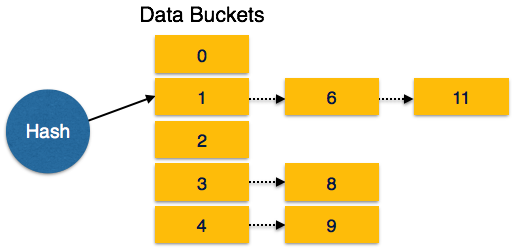
Bucket Overflow – سرریز Bucket
وضعیت bucket-overflow یک وضعیت تصادم و برخورد است که برای اصلاً برای تابع hash مطلوب نیست. در این حالت می توان از زنجیره ای سرریز استفاده کرد.
- Overflow Chaining – هنگامی که Bucket ها پر هستند ، یک Bucket جدید برای همان نتیجه هش اختصاص داده می شود و بعد از مورد قبلی به هم وصل می شود. این مکانیسم Closed Hashing نام دارد.
آشنایی با Hashing در سیستم مدیریت پایگاه داده ( DBMS )
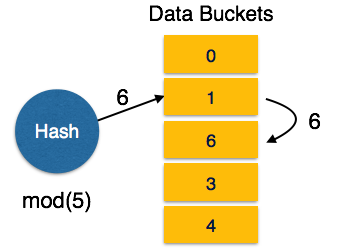
- Linear Probing – هنگامی که یک تابع hash آدرسی را برای داده هایی که از قبل ذخیره شده باشند؛ تولید می کند Bucket خالی بعدی به آن اختصاص می یابد. به این مکانیسم Open Hashing گفته می شود.
آشنایی با Hashing در سیستم مدیریت پایگاه داده ( DBMS )
Dynamic Hashing – هشینگ پویا
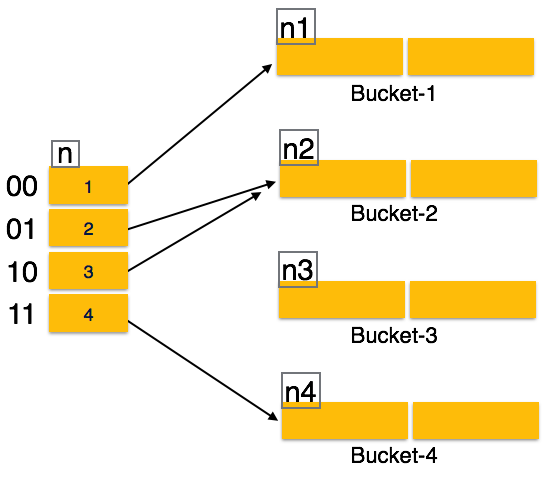
مشکل Static Hashing یا هشینگ ثابت این است که با رشد یا کوچک شدن اندازه پایگاه داده، بطور پویا گسترش نمی یابد یا کوچک نمی شود. اما Dynamic Hashing یا هشینگ پویا مکانیزمی را فراهم می کند که Bucket داده ها به صورت پویا و بر حسب تقاضا اضافه و حذف می شوند. Dynamic Hashing همچنین به عنوان extended hashing نیز شناخته می شود.
در Dynamic Hashing تابع function؛ برای تولید تعداد زیادی از مقادیر ساخته شده و در ابتدا فقط تعداد کمی از آن استفاده می شود.
آشنایی با Hashing در سیستم مدیریت پایگاه داده ( DBMS )
Organization سازمان
پیشوند کل مقدار hash به عنوان index هش در نظر گرفته می شود که فقط بخشی از مقدار hash برای محاسبه آدرس Bucket استفاده می شود. هر index برای هر hash یک مقدار عمق دارد تا مشخص کند که چند بیت برای محاسبه یک تابع hash استفاده می شود. این بیت ها می توانند ۲n bucket ها را برطرف کنند. هنگامی که تمام این بیت ها مصرف می شوند – یعنی وقتی تمام Bucket ها پر هستند – مقدار عمق به صورت خطی افزایش می یابد و دو برابر Bucket ها برای اختصاص دهی استفاده می شود.
عملیاتی سازی
- Querying – به مقدار عمق index هش نگاه کنید و از آن بیت ها برای محاسبه آدرس Bucket استفاده کنید.
- Update – همانند بالا یک کوئری را انجام داده و داده را به روز کنید.
- Deletion – برای یافتن داده های مورد نظر و حذف همان ، یک کوئری انجام دهید.
- Insertion – آدرس Bucket را محاسبه کنید.
– اگر Bucket از قبل پر است:
– Bucket های بیشتری به آن اضافه کنید.
– بیت های اضافی را به مقدار hash اضافه کنید.
– تابع hash را دوباره محاسبه کنید.
– علاوه بر این:
– داده را به Bucket اضافه کنید:
– اگر تمام Bucket ها پر است؛ از static hashing استفاده کنید.
هنگامی که داده ها به ترتیب سازمان یافته نیستند و کوئری ها به طیف وسیعی از داده ها نیاز دارند؛ استفاده از Hashing مناسب نیست. وقتی داده ها گسسته و تصادفی هستند، Hash بهترین انتخاب است.
الگوریتم های Hashing پیچیدگی بالایی نسبت به indexing دارند. تمام عملیات hash در زمان ثابت انجام می شود.
سخن پایانی
در این جلسه به آشنایی با Hashing در سیستم مدیریت پایگاه داده ( DBMS ) پرداختیم؛ برای یک ساختار بزرگ پایگاه داده؛ جستجو برای یافتن تمام مقادیر index از طریق تمام سطح آن و سپس رسیدن به بلوک داده مقصد برای بازیابی اطلاعات مورد نظر؛ تقریباً کار خیلی خیلی سختی است. اما دست ما آنچنان هم خالی نیست! Hashing یک تکنیک مؤثر برای محاسبه محل مستقیم رکورد داده بر روی دیسک بدون استفاده از ساختار index است.
در جلسه بعدی می خواهیم به به سراغ موضوع Transaction در DBMS برویم.
با پی وی لرن همراه باشید.
")




